테이블 자체의 데이터에 의존하는 조건으로 테이블의 행을 검색할 필요가 있을 때 서브쿼리를 사용하는 것이 유용하다.
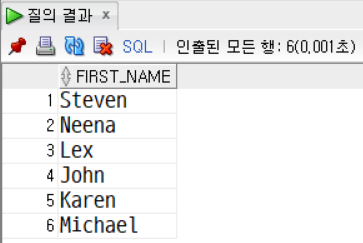
-- 'Nancy'의 급여보다 급여가 많은 사람을 검색한다.
SELECT salary FROM employees WHERE first_name = 'Nancy';
SELECT first_name FROM employees WHERE salary > 12008;
서브쿼리를 사용하려면 () 괄호 안에 명시하고, 서브쿼리절의 리턴행이 1줄 이하여야 한다.
서브쿼리는 비교할 대상이 반드시 하나 들어가야 한다.
쿼리를 해석할 때 서브쿼리절을 먼저 해석한다.
SELECT * FROM employees
WHERE salary > (SELECT salary
FROM employees
WHERE first_name = 'Nancy');
-- emplyee_id가 103번인 사람과 job_id가 동일한 사람을 검색하는 문장
SELECT * FROM employees
WHERE job_id = (SELECT job_id
FROM employees
WHERE employee_id = 130);
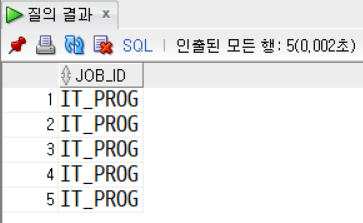
서브쿼리의 리턴 행이 여러 개인 경우 사용할 수 없으며, 에러가 난다.
SELECT * FROM employees
WHERE job_id = (SELECT job_id
FROM employees
WHERE job_id = 'IT_PROG'); -- 에러
IT_PROG만 조회했을 때 5개의 행이 리턴되는 것을 확인할 수 있다.
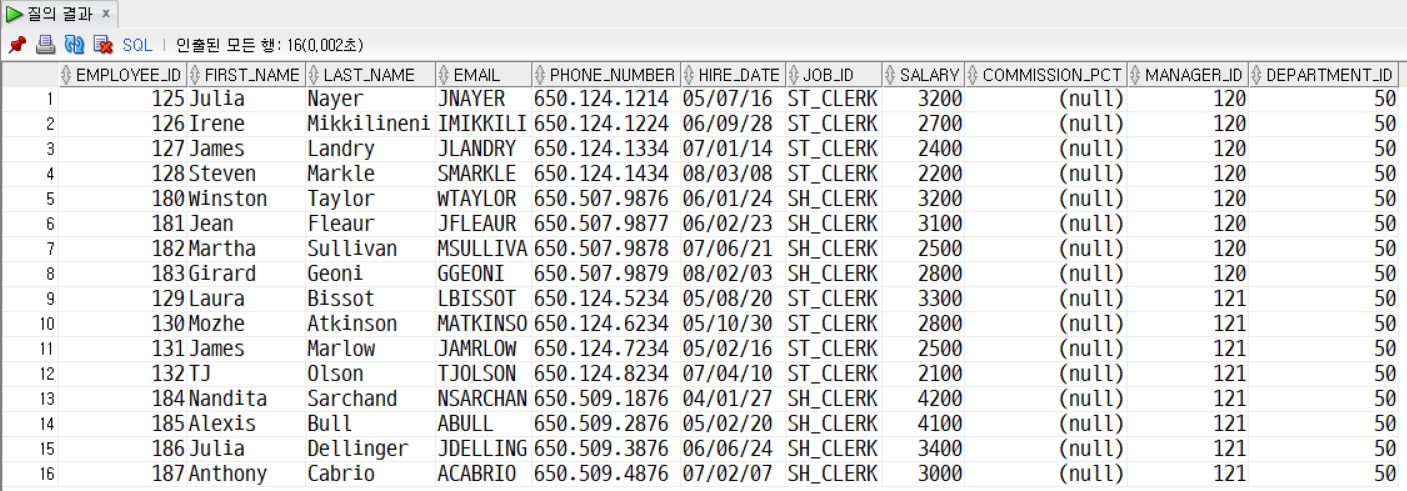
여러 행이 리턴되는 에러를 다중행 연산자를 사용해서 서브쿼리를 작성할 수 있다. (IN)
SELECT * FROM employees
WHERE job_id IN (SELECT job_id
FROM employees
WHERE job_id = 'IT_PROG');
-- first_name이 David인 사람 중 가장 작은 값보다 급여가 큰 사람을 조회
SELECT *
FROM employees
WHERE salary > (SELECT salary
FROM employees
WHERE first_name = 'David');
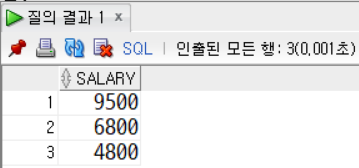
ANY : 값을 서브쿼리에 의해 리턴된 각각의 값과 비교해서,하나라도 만족하면 실행 결과를 얻을 수 있다.
SELECT *
FROM employees
WHERE salary > ANY (SELECT salary
FROM employees
WHERE first_name = 'David');
SALARY가 4800, 6800, 9500 중 하나만 만족하면 결과를 얻을 수 있기 때문에 4800 이상의 결과를 얻을 수 있다.
ALL : 값을 서브쿼리에 의해 리턴된 모든 값과 비교해서,모두 만족해야 실행 결과를 얻을 수 있다.
SELECT *
FROM employees
WHERE salary > ALL (SELECT salary
FROM employees
WHERE first_name = 'David');
SALARY가 4800, 6800, 9500 중 모두 만족해야 결과를 얻을 수 있기 때문에 9500 이상의 결괏값만 나온다.
Scalar Sub Query (스칼라 서브쿼리)
SELECT 구문에 서브쿼리를 사용하고, LEFT OUTER JOIN과 같은 결과와 같다.
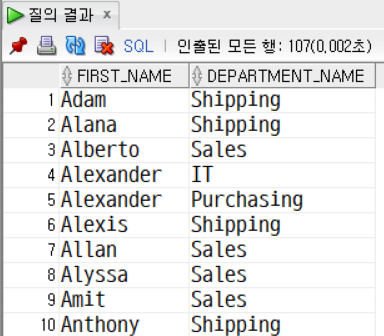
SELECT e.first_name, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON e.department_id = d.department_id
ORDER BY first_name ASC;
SELECT
first_name,
(SELECT department_name
FROM departments d
WHERE d.department_id = e.department_id) AS department_name
FROM employees e
ORDER BY first_name ASC;
스칼라 서브쿼리가 조인보다 좋은 경우
함수처럼 한 레코드당 정확히 하나의 값만을 리턴할 때
조인이 스칼라 서브쿼리보다 좋은 경우
조회할 데이터가 대용량인 경우, 해당 데이터가 수정이 빈번한 경우
-- LEFT JOIN
SELECT
d.*, e.first_name
FROM departments d
LEFT JOIN employees e
ON d.manager_id = e.employee_id
ORDER BY d.department_id ASC;
-- Scalar sub query
SELECT
d.*,
(SELECT first_name
FROM employees e
WHERE e.employee_id = d.manager_id) AS manager_name
FROM departments d
ORDER BY d.manager_id ASC;
-- 각 부서별 사원 수 출력 (departments 테이블의 name과 사원수 별칭을 지어서 출력)
SELECT
d.department_name,
(SELECT COUNT(*)
FROM employees e
WHERE e.department_id = d.department_id
GROUP BY department_id) AS 사원수
FROM departments d;
Inline View(인라인 뷰)
FROM 구문에 서브쿼리를 사용하고,순번을 정해놓은 조회 자료를 범위로 지정해서 가지고 온다.
SELECT ROWNUM AS rn, employee_id, first_name, salary
FROM employees
ORDER BY salary DESC;
salary로 정렬을 진행하면서 ROWNUM을 붙이면ROWNUM 정렬이 되지 않는 결과가 발생한다.
이유: ROWNUM을 붙이고 정렬이 진행하기 때문. ORDER BY는 항상 마지막에 진행한다.
해결: 정렬을 미리 지정해서 ROWNUM을 붙여야 한다.
SELECT * FROM
(
SELECT ROWNUM AS rn, tbl.*
FROM
(
SELECT first_name, salary
FROM employees
ORDER BY salary DESC
) tbl
);
ROWNUM을 붙이고 나서 범위를 지정해서 조회하면범위 지정이 불가능하고, 지목할 수 없다는 문제가 발생한다.
이유: WHERE절부터 먼저 실행하고 나서 ROWNUM이 SELECT되기 때문이다.
해결: ROWNUM까지 붙여 놓고 다시 한번 자료를 SELECT해서 범위를 지정해야 한다.
가장 안쪽 SELECT절에서 필요한 테이블 형식을 생성한다.
바깥쪽 SELECT 절에서 ROWNUM을 붙여서 다시 조회한다.
가장 바깥쪽 SELECT절에서 이미 붙어있는 ROWNUM의 범위를 지정해서 조회한다.
SQL 실행 순서
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
SQL Quiz
문제1. EMPLOYEES 테이블에서 모든 사원들의 평균급여보다 높은 사원들의 데이터를 출력한다. (AVG(컬럼) 사용) EMPLOYEES 테이블에서 모든 사원들의 평균급여보다 높은 사원들의 수를 출력한다. EMPLOYEES 테이블에서 job_id 가 IT_PFOG 인 사원들의 평균급여보다 높은 사원들의 데이터를 출력한다.
SELECT * FROM employees
WHERE salary > (SELECT AVG(salary)
FROM employees);
SELECT COUNT(*) FROM employees
WHERE salary > (SELECT AVG(salary)
FROM employees);
SELECT * FROM employees
WHERE salary > (SELECT AVG(salary)
FROM employees
WHERE job_id = 'IT_PROG');
문제2. DEPARTMENTS 테이블에서 manager_id 가 100 인 사람의 department_id 와 EMPLOYEES 테이블에서 department_id 가 일치하는 모든 사원의 정보를 검색한다.
SELECT *
FROM employees
WHERE department_id = (SELECT department_id
FROM departments
WHERE manager_id = 100);
문제3. EMPLOYEES 테이블에서 "Pat"의 manager_id 보다 높은 manager_id 를 갖는 모든 사원의 데이터를 출력한다. EMPLOYEES 테이블에서 "James"(2명) 들의 manager_id 와 같은 모든 사원의 데이터를 출력한다.
SELECT * FROM employees
WHERE manager_id > (SELECT manager_id
FROM employees
WHERE first_name = 'Pat');
SELECT * FROM employees
WHERE manager_id IN (SELECT manager_id
FROM employees
WHERE first_name = 'James');
문제4. EMPLOYEES 테이블 에서 first_name 기준으로 내림차순 정렬하고, 41~50번째 데이터의 행 번호, 이름을 출력한다.
SELECT * FROM
(
SELECT ROWNUM AS rn, first_name FROM
(
SELECT * FROM employees
ORDER BY first_name DESC
)
)
WHERE rn > 40 AND rn <= 50;
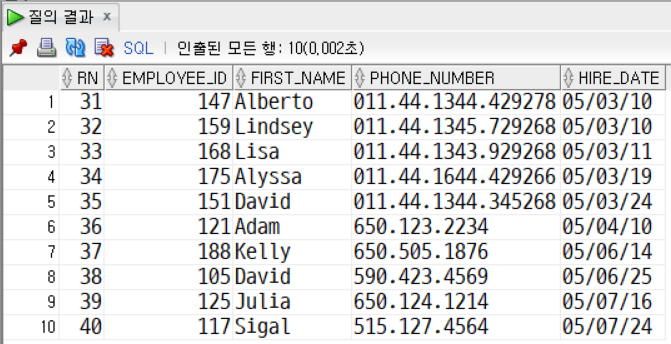
문제5. EMPLOYEES 테이블에서 hire_date 기준으로 오름차순 정렬하고, 31~40 번째 데이터의 행 번호, 사원 id, 이름, 번호, 입사일을 출력한다.
SELECT * FROM
(
SELECT ROWNUM AS rn, tbl.*
FROM
(
SELECT employee_id, first_name, phone_number, hire_date FROM employees
ORDER BY hire_date ASC
) tbl
)
WHERE rn > 30 AND rn <= 40;
SELECT
e.employee_id,
CONCAT(e.first_name, e.last_name) AS 이름,
e.department_id,
d.department_name
FROM employees e LEFT OUTER JOIN departments d
ON e.department_id = d.department_id
ORDER BY e.employee_id ASC;
문제7. 문제6의 결과를 스칼라 쿼리 로 동일하게 조회한다.
SELECT
e.employee_id,
CONCAT(first_name, last_name) AS 이름,
e.department_id,
(
SELECT d.department_name
FROM departments d
WHERE e.department_id = d.department_id
) AS department_name
FROM employees e
ORDER BY e.employee_id ASC;
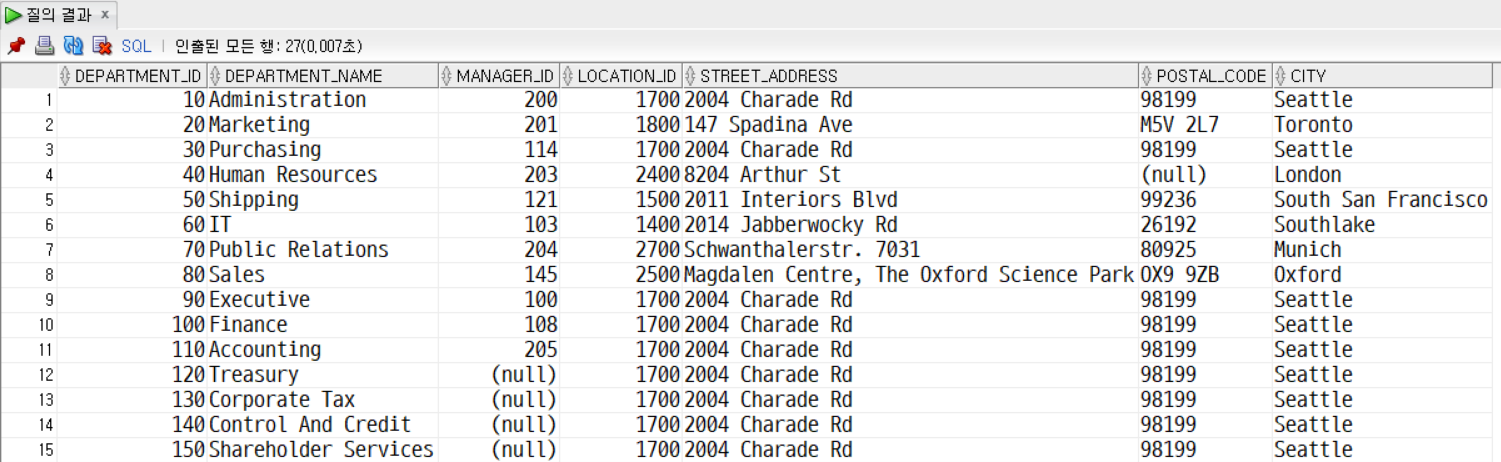
문제8. DEPARTMENTS 테이블 LOCATIONS 테이블을 left 조인한다. 조건) 부서아이디, 부서이름, 매니저아이디, 로케이션아이디, 스트릿 어드레스, 포스트 코드, 시티만 출력한다. 조건) 부서아이디 기준 오름차순 정렬
SELECT
d.department_id,
d.department_name,
d.manager_id,
d.location_id,
loc.street_address,
loc.postal_code,
loc.city
FROM departments d LEFT OUTER JOIN locations loc
ON d.location_id = loc.location_id
ORDER BY d.department_id ASC;
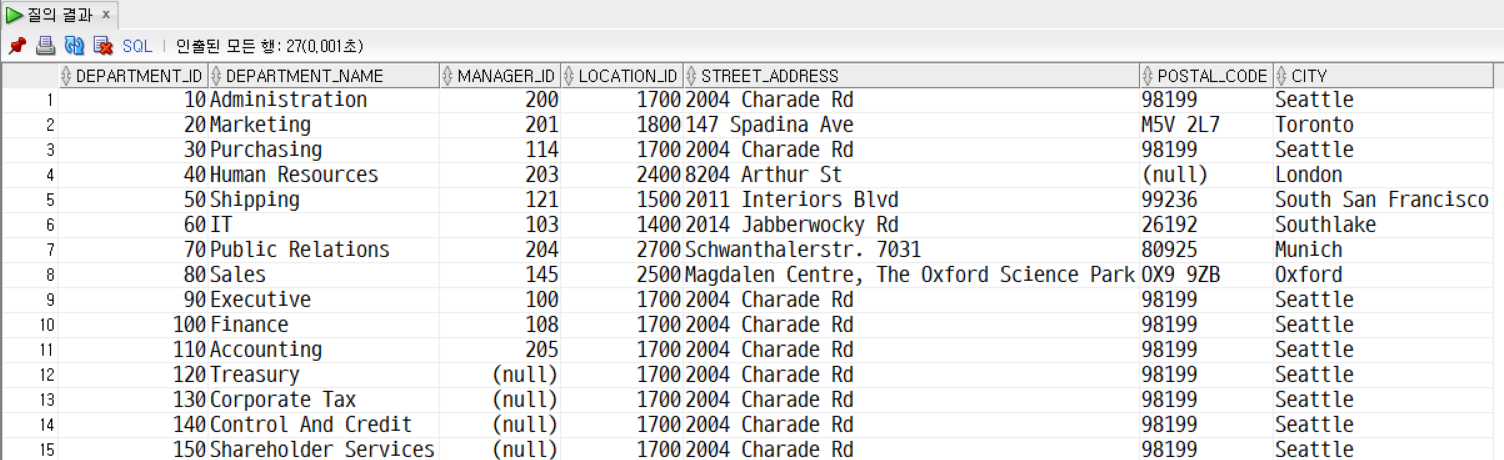
문제9. 문제8의 결과를 스칼라 쿼리로 동일하게 조회한다.
SELECT
d.department_id,
d.department_name,
d.manager_id,
d.location_id,
(SELECT loc.street_address
FROM locations loc
WHERE d.location_id = loc.location_id) AS street_address,
(SELECT loc.postal_code
FROM locations loc
WHERE d.location_id = loc.location_id) AS postal_code,
(SELECT loc.city
FROM locations loc
WHERE d.location_id = loc.location_id) AS city
FROM departments d
ORDER BY d.department_id ASC;
- 스칼라 서브의 경우 반드시 한 행 한컬럼만 리턴하는 서브쿼리이다. - 단일행, 한 컬럼만 반환하기 때문에 조회할 행의 값을 반환하려면 하나씩 작성해야 한다.
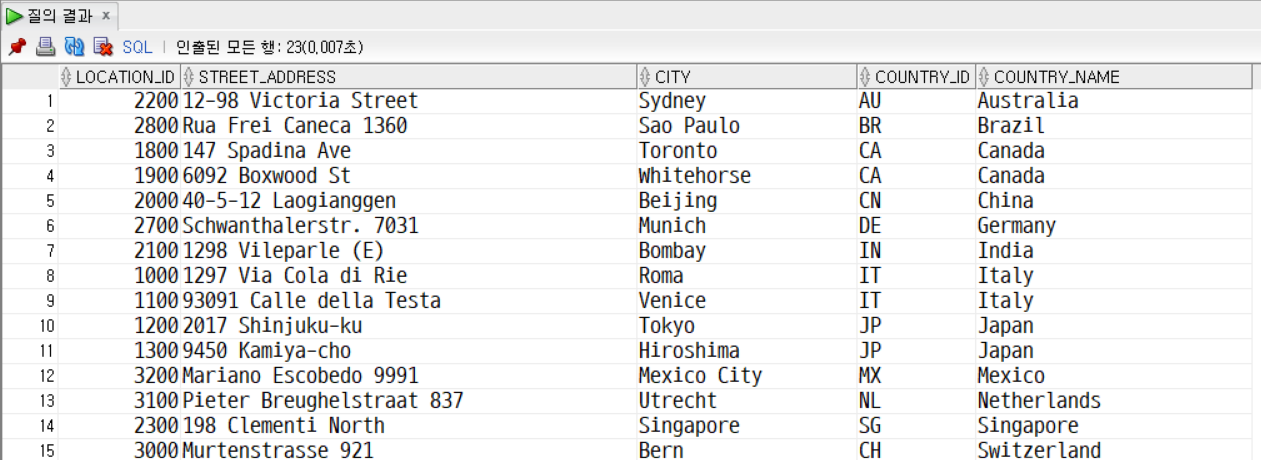
문제10. LOCATIONS 테이블 COUNTRIES 테이블을 left 조인한다. 조건) 로케이션아이디, 주소, 시티, country_id, country_name만 출력한다. 조건) country_name 기준 오름차순 정렬
SELECT
loc.location_id,
loc.street_address,
loc.city,
loc.country_id,
c.country_name
FROM locations loc LEFT OUTER JOIN countries c
ON loc.country_id = c.country_id
ORDER BY c.country_name ASC;
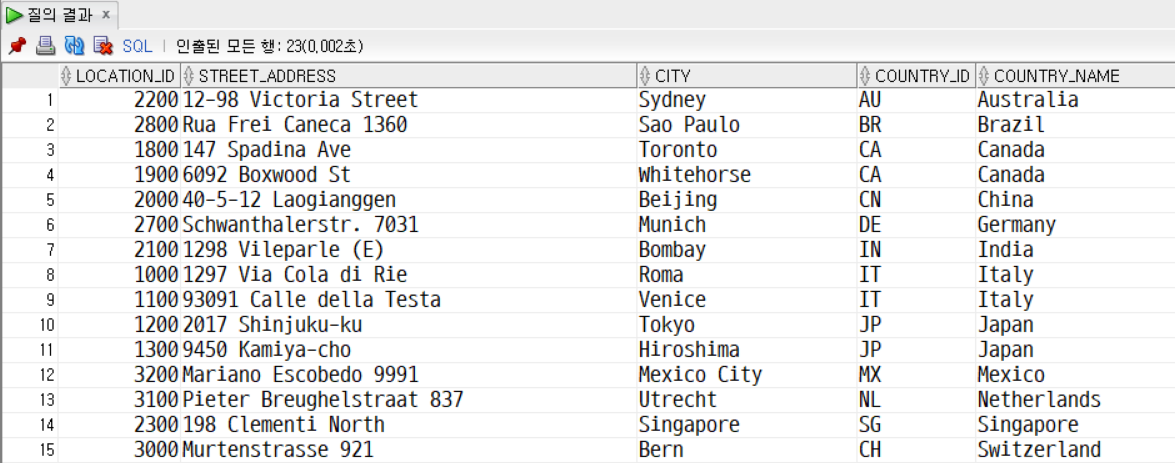
문제11. 문제10의 결과를 스칼라 쿼리로 동일하게 조회한다.
SELECT
loc.location_id,
loc.street_address,
loc.city,
loc.country_id,
(
SELECT country_name
FROM countries c
WHERE loc.country_id = c.country_id
) AS country_name
FROM locations loc
ORDER BY country_name ASC;
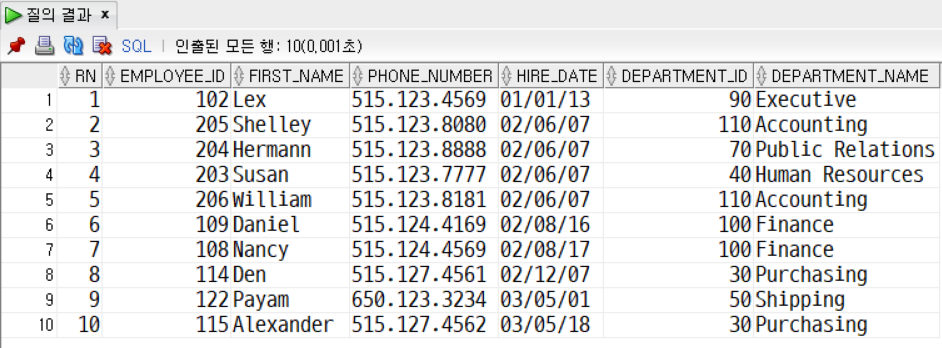
문제12. EMPLOYEES 테이블, DEPARTMENT 테이블을 left 조인 hire_date를 오름차순 기준으로 1~10번째 데이터만 출력한다.
조건) rownum을 적용해서 번호, 직원아이디, 이름, 전화번호, 입사일, 부서아이디, 부서이름을 출력한다. 조건) hire_date 를 기준으로 오름차순 정렬 되어야 하고, rownum이 틀어지면 안 된다.
SELECT *
FROM
(
SELECT ROWNUM AS rn, tbl.*
FROM
(
SELECT
e.employee_id,
e.first_name,
e.phone_number,
e.hire_date,
d.department_id,
d.department_name
FROM employees e LEFT OUTER JOIN departments d
ON e.department_id = d.department_id
ORDER BY hire_date ASC
) tbl
)
WHERE rn >= 1 AND rn <= 10;
-- Scalar SubQuery
SELECT *
FROM
(
SELECT ROWNUM AS rn, tbl.*
FROM
(
SELECT
e.employee_id,
e.first_name,
e.phone_number,
e.hire_date,
e.department_id,
(
SELECT department_name
FROM departments d
WHERE e.department_id = d.department_id
) AS department_name
FROM employees e
ORDER BY hire_date ASC
) tbl
)
WHERE rn >= 1 AND rn <= 10;
SELECT
e.last_name,
e.job_id,
d.department_id,
d.department_name
FROM employees e LEFT OUTER JOIN departments d
ON e.department_id = d.department_id
WHERE job_id = 'SA_MAN';
SELECT a.*, d.department_name
FROM
(
SELECT
last_name,
job_id,
department_id
FROM employees
WHERE job_id = 'SA_MAN'
) a
JOIN departments d
ON a.department_id = d.department_id;
-- Scalar SubQuery
SELECT
e.last_name,
e.job_id,
(
SELECT department_id
FROM departments d
WHERE e.department_id = d.department_id
) AS department_id,
(
SELECT department_name
FROM departments d
WHERE e.department_id = d.department_id
) AS department_name
FROM employees e
WHERE job_id = 'SA_MAN';
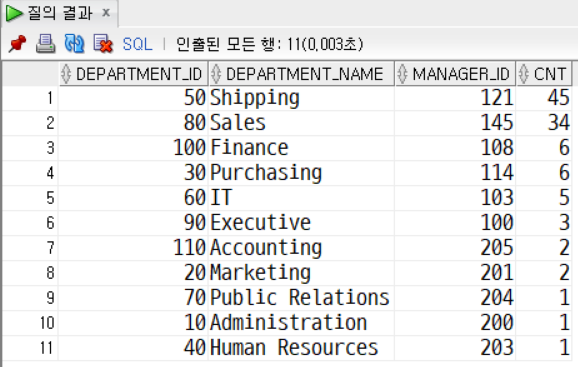
문제14 DEPARTMENT 테이블에서 각 부서의 ID, NAME, MANAGER_ID 와 부서에 속한 인원수를 출력한다.
조건) 인원수 기준 내림차순 정렬한다. 조건) 사람이 없는 부서는 출력하지 않는다.
SELECT
d.department_id,
d.department_name,
d.manager_id,
a.total
FROM departments d
INNER JOIN (
SELECT
department_id,
COUNT(*) AS total
FROM employees e
GROUP BY department_id
) a
ON d.department_id = a.department_id
ORDER BY a.total DESC;
SELECT
d.department_id,
d.department_name,
d.manager_id,
c.cnt
FROM departments d
LEFT JOIN (
SELECT
e.department_id,
COUNT(*) AS cnt
FROM employees e
GROUP BY e.department_id
) c
ON d.department_id = c.department_id
WHERE c.department_id IS NOT NULL
ORDER BY cnt DESC;
문제15 부서에 대한 정보 전부와, 주소, 우편번호, 부서별 평균 연봉을 구해서 출력한다.
조건) 부서별 평균이 없으면 0 으로 출력한다.
SELECT d.*,
loc.street_address,
loc.postal_code,
nvl(a.salary, 0) AS salary
FROM departments d LEFT JOIN
(
SELECT e.department_id,
TO_CHAR(TRUNC(AVG(salary * 12), 0), '999,999') AS salary
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
GROUP BY e.department_id
) a
ON d.department_id = a.department_id
LEFT JOIN locations loc
ON d.location_id = loc.location_id;
SELECT
d.*,
loc.street_address,
loc.postal_code,
nvl(a.result, 0) AS 부서별평균급여
FROM departments d
INNER JOIN locations loc
ON d.location_id = loc.location_id
LEFT OUTER JOIN
(
SELECT department_id,
TRUNC(AVG(salary * 12)) AS result
FROM employees
GROUP BY department_id
) a
ON d.department_id = a.department_id;
문제16 문제15 결과에 대해 DEPARTMENT_ID 기준으로 내림차순 정렬해서 ROWNUM 을 붙여 1~10 데이터까지만 출력한다.
SELECT *
FROM
(
SELECT ROWNUM AS rn, tbl.*
FROM(
SELECT d.*,
loc.city,
loc.postal_code,
nvl(a.salary, 0) as salary
FROM departments d LEFT JOIN
(
SELECT e.department_id,
to_char(trunc(avg(salary * 12), 0), '999,999') as salary
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id
GROUP BY e.department_id
) a
ON d.department_id = a.department_id
LEFT JOIN locations loc
ON d.location_id = loc.location_id
ORDER BY d.department_id
) tbl
)
WHERE rn >= 1 AND rn <= 10;
SELECT *
FROM
(
SELECT ROWNUM AS rn, tbl.*
FROM
(
SELECT
d.*,
loc.street_address,
loc.postal_code,
nvl(a.result, 0) AS 부서별평균급여
FROM departments d
INNER JOIN locations loc
ON d.location_id = loc.location_id
LEFT OUTER JOIN
(
SELECT department_id,
TRUNC(AVG(salary * 12)) AS result
FROM employees
GROUP BY department_id
) a
ON d.department_id = a.department_id
) tbl
)
WHERE rn >= 1 AND rn <= 10;
DML(Data Manipulation Language)
Insert
테이블 구조 확인 DESCRIBE
DESCRIBE 대신 DESC를 사용해도 된다.
DESCRIBE departments;
DESC departments;
INSERT를 사용할 때 모든 컬럼 데이터를 한번에 지정한다.
타입에 맞는 값을 지정해서 삽입해야 한다.
문자나 숫자 타입으로 지정된 곳에 타입이 맞지 않는 데이터를 집어 넣을 때는 자동 형변환을 해준다.
INSERT INTO departments
VALUES (280, '개발자', null, 1700);
INSERT INTO departments
VALUES ('300', '개발자', null, 1700);
INSERT INTO departments
VALUES ('300', null, null, 1700); -- 오류 2번째 null을 넣을 수 없다.
INSERT INTO departments
VALUES ('301', 23.3, null, 1700);
INSERT INTO departments
VALUES ('300', 23.3, null, 1700);
INSERT INTO departments
VALUES ('301%', 23.3, null, 1700); -- 오류 1번째 특수기호를 넣을 수 없다.
-- 제약조건 삭제
ALTER TABLE emps DROP CONSTRAINT emps_manager_fk;
ALTER TABLE emps DROP CONSTRAINT emps_emp_id_pk;
UPDATE를 진행할 때는 주의해야 할 부분은 Where를 이용해서 어떤 값을 수정할 지 지목해야 한다.
지목을 하지 않을 경우 수정 대상이 테이블 전체로 지목된다.
UPDATE emps SET salary = 30000
WHERE employee_id = 100;
UPDATE emps SET salary = salary + salary * 0.1
WHERE employee_id = 100;
UPDATE emps SET manager_id = 100
WHERE employee_id = 100;
UPDATE emps SET
phone_number = '515.123.4566', manager_id = 102
WHERE employee_id = 100;
-- UPDATE (서브쿼리)
UPDATE emps
SET (job_id, salary, manager_id) =
(SELECT job_id, salary, manager_id
FROM emps
WHERE employee_id = 100)
WHERE employee_id = 101;
Delete
DELETE FROM emps
WHERE employee_id = 103;
-- DELETE (서브쿼리)
DELETE FROM emps
WHERE department_id = (SELECT department_id FROM departments
WHERE department_id = 100);
DELETE FROM emps
WHERE department_id = (SELECT department_id FROM departments
WHERE department_name = 'IT');
DELETE FROM departments WHERE department_id = 50;
Merge
MERGE는 테이블 병합으로, UPDATE와 INSERT를 한번에 처리한다.
한 테이블에 해당하는 데이터가 있으면 UPDATE 없으면 INSERT로 처리.
만약 MERGE가 없다면 해당 데이터의 존재 유무를 일일이 확인해야 하고, if문을 사용해서 데이터가 있으면 UPDATE, 없으면 else문 사용해서 INSERT를 처리하도록 진행해야 하는데 MERGE를 통해 쉽게 처리 가능하다.
MERGE INTO emps_it a -- (MERGE 할 타켓 테이블)
USING -- 병합시킬 데이터
(SELECT * FROM employees WHERE job_id = 'IT_PROG') b -- 조인구문
ON -- 병합시킬 데이터의 연결 조건
(a.employee_id = b.employee_id) -- 조인 조건
WHEN MATCHED THEN -- 조건에 일치할 경우 타켓 테이블에 실행
UPDATE SET
a.phone_number = b.phone_number,
a.hire_date = b.hire_date,
a.salary = b.salary,
a.commission_pct = b.commission_pct,
a.manager_id = b.manager_id,
a.department_id = b.department_id
WHEN NOT MATCHED THEN -- 조건에 일치하지 않는 경우 타겟테이블에 실행
INSERT /*속성(컬럼)*/ VALUES
(b.employee_id, b.first_name, b.last_name,
b.email, b.phone_number, b.hire_date, b.job_id,
b.salary, b.commission_pct, b.manager_id, b.department_id);
DELETE WHERE 문을 사용할 때 주의점
DELETE만 단독으로 쓸 수 없다.
UPDATE 이후 DELETE 작성이 가능하다.
삭제할 대상 컬럼들을 동일한 값으로 먼저 UPDATE를 진행하고 DELETE의 WHERE절에 지정한 동일한 값을 지정해서 삭제한다.
MERGE INTO emps_it a
USING
(SELECT * FROM employees) b
ON
(a.employee_id = b.employee_id)
WHEN MATCHED THEN
UPDATE SET
a.email = b.email,
a.phone_number = b.phone_number,
a.salary = b.salary,
a.commission_pct = b.commission_pct,
a.manager_id = b.manager_id,
a.department_id = b.department_id
WHEN NOT MATCHED THEN
INSERT VALUES
(b.employee_id, b.first_name, b.last_name,
b.email, b.phone_number, b.hire_date, b.job_id,
b.salary, b.commission_pct, b.manager_id, b.department_id);