SELECT
first_name,
NVL(commission_pct, 0) AS comm_pct
FROM employees;
NULL 제거 함수 NVL2(컬럼, null이 아닐 경우 값, null일 경우 값)
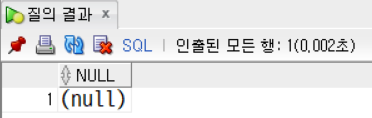
SELECT NVL2(null, '널아님', '널') FROM dual;
SELECT NVL2(50, '널아님', '널') FROM dual;
SELECT first_name, NVL2(commission_pct, 'true', 'false')
FROM employees;
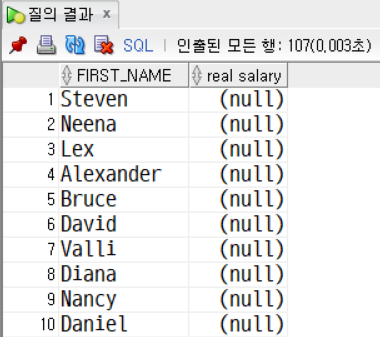
SELECT
first_name,
commission_pct,
NVL2(commission_pct, salary + (salary * commission_pct), salary) AS real_salary
FROM employees;
SELECT
first_name,
salary + (salary * commission_pct) AS real_salary
FROM employees;
SELECT
first_name,
salary + (salary * commission_pct) AS "real salary"
FROM employees; -- 언더바(_)를 사용하지 않고 띄어쓰기를 하고 싶을 때 쌍따옴표(") 사용
DECODE(컬럼 혹은 표현식, 항목1, 결과1, 항목2, 결과2 ..... default)
SELECT
DECODE('B', 'A', 'A입니다', 'B', 'B입니다', 'C', 'C입니다', '정확한 문자를 입력해주세요.')
FROM dual;
SELECT
DECODE('Z', 'A', 'A입니다', 'B', 'B입니다', 'C', 'C입니다', '정확한 문자를 입력해주세요.')
FROM dual;
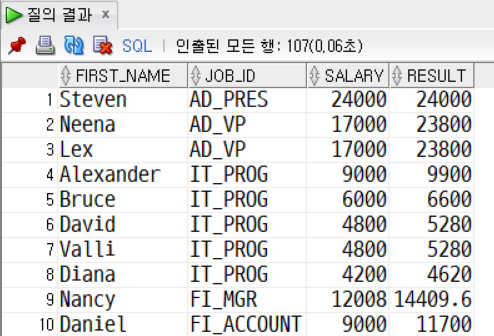
SELECT
job_id,
salary,
DECODE(job_id, 'IT_PROG', salary * 1.1, 'FI_MGR', salary * 1.2, 'AD_VP', salary * 1.3, salary) AS result
FROM employees;
CASE WHEN THEN END
SELECT
first_name,
job_id,
salary,
(
CASE job_id
WHEN 'IT_PROG' THEN salary * 1.1
WHEN 'FI_MGR' THEN salary * 1.2
WHEN 'FI_ACCOUNT' THEN salary * 1.3
WHEN 'AD_VP' THEN salary * 1.4
ELSE salary
END
) AS result
FROM employees;
SQL Quiz01
문제 1. 현재일자를 기준으로 EMPLOYEES 테이블의 입사일자(hire_date)를 참조해서 근속년수가 10년 이상인 사원을 다음과 같은 형태의 결과를 출력하도록 쿼리를 작성한다.
조건1) 근속년수가 높은 사원 순서대로 결과가 나오도록 한다.
SELECT
employee_id AS 사원번호,
CONCAT(first_name, last_name) AS 사원명,
hire_date AS 입사일자,
TRUNC((SYSDATE - hire_date)/395) AS 근속년수
FROM employees
WHERE (SYSDATE-hire_date)/365 >= 10
ORDER BY 근속년수 DESC;
SELECT
first_name,
manager_id,
DECODE(manager_id, 100, '사원', 120, '주임', 121, '대리', 122, '과장', '임원') AS 직급
FROM employees
WHERE department_id = 50;
집합 연산자
UNION(합집합 중복x), UNION ALL(합집합 중복o), INTERSECT(교집합), MINUS(차집합)
주의) 집합 연산자를 사용할 때 column 개수가 정확히 일치해야 한다.
SELECT
employee_id, first_name
FROM employees
WHERE hire_date LIKE '04%'
UNION
SELECT
employee_id, first_name
FROM employees
WHERE department_id = 20;
SELECT
employee_id, first_name
FROM employees
WHERE hire_date LIKE '04%'
UNION ALL
SELECT
employee_id, first_name
FROM employees
WHERE department_id = 20;
SELECT
employee_id, first_name
FROM employees
WHERE hire_date LIKE '04%'
INTERSECT
SELECT
employee_id, first_name
FROM employees
WHERE department_id = 20;
SELECT
employee_id, first_name
FROM employees
WHERE hire_date LIKE '04%'
MINUS
SELECT
employee_id, first_name
FROM employees
WHERE department_id = 20;
그룹 함수
SELECT
AVG(salary),
MAX(salary),
MIN(salary),
SUM(salary),
COUNT(*)
FROM employees;
SELECT COUNT(*) FROM employees; -- 총 행 데이터 수
SELECT COUNT(first_name) FROM employees;
SELECT COUNT(commission_pct) FROM employees; -- null이 아닌 행의 수
SELECT COUNT(manager_id) FROM employees; -- null이 아닌 행의 수
-- 부서별로 그룹화, 그룹함수의 사용
SELECT
department_id,
AVG(salary)
FROM employees
GROUP BY department_id;
그룹함수 주의점
그룹함수는 일반 컬럼과 동시에 출력할 수 없다.
GROUP BY절을 사용할 때 GROUP절에 묶이지 않으면 다른 컬럼을 조회할 수 없다.
-- GROUP BY절 2개 이상 사용
SELECT
job_id,
department_id
FROM employees
GROUP BY department_id, job_id
ORDER BY department_id;
-- GROUP BY절의 조건 HAVING절
SELECT
department_id,
SUM(salary)
FROM employees
GROUP BY department_id
HAVING SUM(salary) > 100000;
SELECT
job_id,
COUNT(*)
FROM employees
GROUP BY job_id
HAVING COUNT(*) >= 20;
-- 부서아이디가 50이상인 것들을 그룹화 시키고, 그룹 월급 평균 중 5000 이상만 조회
SELECT
department_id,
AVG(salary) AS 평균
FROM employees
WHERE department_id >= 50
GROUP BY department_id
HAVING AVG(salary) >= 20;
SQL Quiz02
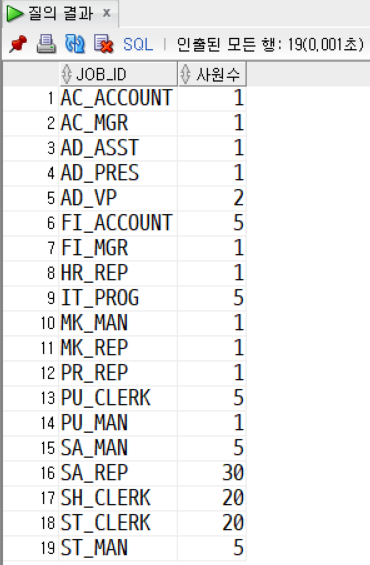
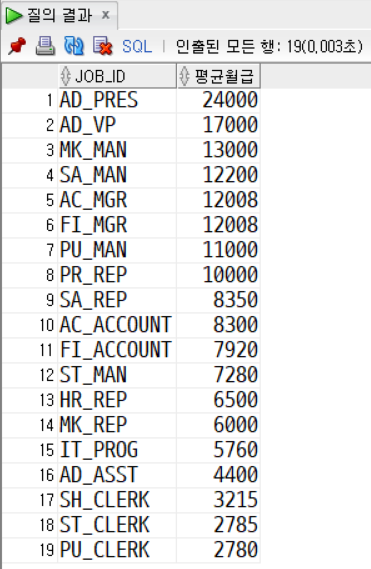
문제1. 사원 테이블에서 JOB_ID별 사원 수를 구한다. 사원 테이블에서 JOB_ID별 월급의 평균을 구하고 월급의 평균 순으로 내림차순 정렬한다.
SELECT job_id, count(*) AS 사원수
FROM employees
GROUP BY job_id;
SELECT job_id, AVG(salary) AS 평균월급
FROM employees
GROUP BY job_id
ORDER BY AVG(salary) DESC;
문제2. 사원 테이블에서 입사년도별 사원 수를 구한다.
SELECT TO_CHAR(hire_date, 'YY'), count(*)
FROM employees
GROUP BY TO_CHAR(hire_date, 'YY');
문제3. 급여가 1000 이상인 사원들의 부서별 평균 급여를 출력한다. 단, 부서 평균 급여가 2000이상인 부서만 출력
SELECT department_id, AVG(salary)
FROM employees
WHERE salary >= 1000
GROUP BY department_id
HAVING AVG(salary) >= 2000;
문제4. 사원 테이블에서 commission_pct(커미션) 컬럼이 null이 아닌 사람들의 department_id(부서별) salary(월급)의 평균, 합계 count를 구한다.
조건1) 월급의 평균은 커미션을 적용시킨 월급이다. 조건2) 평균은 소수 2째 자리에서 절삭한다.
SELECT
department_id,
TRUNC(AVG(salary + salary * commission_pct), 2) AS 평균,
SUM(salary + salary * commission_pct) AS 합계,
COUNT(*)
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY department_id;
JOIN
두개의 테이블을 서로 연관해서 조회하는 것을 조인이라 부른다.
하나 이상의 테이블로부터 데이터를 질의하기 위해서 조인을 사용한다.
하나 이상의 테이블에 똑같은 열 이름이 있을 때 열 이름 앞에 테이블 이름을 붙인다.
오라클 조인 구문과ANSI 조인구문이 있다.
내부 조인
오라클 문법
-- employees 테이블의 부서 id와 일치하는 departments 테이블의 부서 id 찾는다.
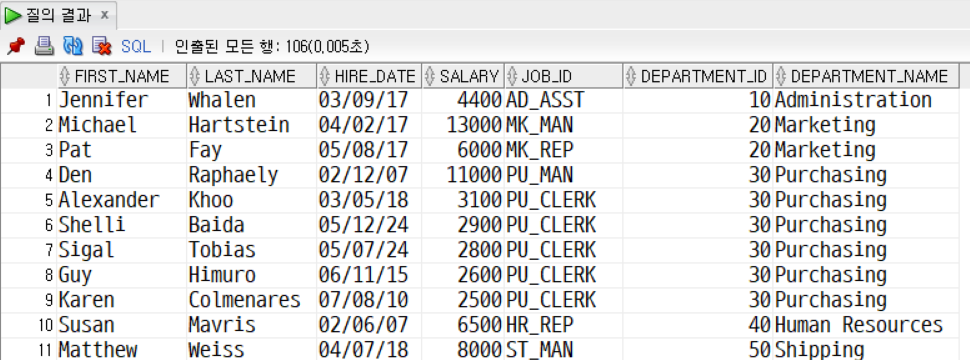
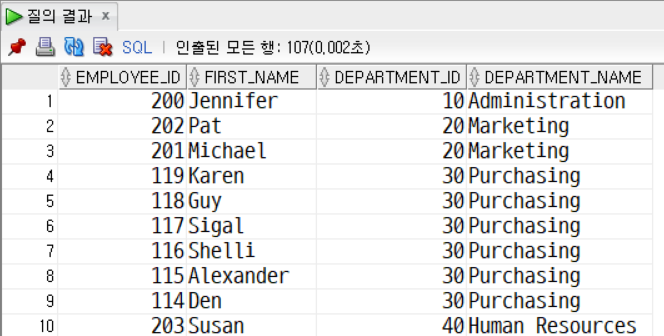
SELECT
e.first_name, e.last_name, e.hire_date,
e.salary, e.job_id, e.department_id, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id;
ANSI 표준 문법
SELECT
e.first_name, e.last_name, e.hire_date,
e.salary, e.job_id, e.department_id, d.department_name
FROM employees e INNER JOIN departments d
ON e.department_id = d.department_id;
-- 3개의 테이블을 이용한 내부 조인
-- 내부 조인: 두 테이블 모두 일치하는 값을 가진 행만 반환한다.
SELECT
e.first_name, e.last_name, e.department_id,
d.department_name,
j.job_title
FROM employees e, departments d, jobs j
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id;
-- 조인 조건과 함께 사용되는 일반 조건이 있을 경우
SELECT
e.first_name, e.last_name, e.department_id,
d.department_name, e.job_id, j.job_title, loc.city
FROM employees e, departments d, jobs j, locations loc
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND d.location_id = loc.location_id
AND loc.state_province = 'California';
외부 조인
상호 테이블간 일치되는 값으로 연결되는 내부조인과는 달리 어느 한 테이블에 공통 값이 없더라도 해당 row들이 조회 결과에 모두 포함되는 조인을 말한다.
SELECT
e.employee_id, e.first_name,
e.department_id, d.department_name
FROM employees e, departments d, locations loc
WHERE e.department_id = d.department_id(+)
AND d.location_id = loc.location_id;
employees 테이블에는 존재하고, departments 테이블에는 존재하지 않아도 (+)가 붙지 않은 테이블을 기준으로 departments 테이블이 조인에 참여하라는 의미를 부여하기 위해 기호를 붙인다. 외부조인을 사용하더라도 AND나 다른 조건으로 내부 조인을 사용하면 내부조인이 우선적으로 인식한다.
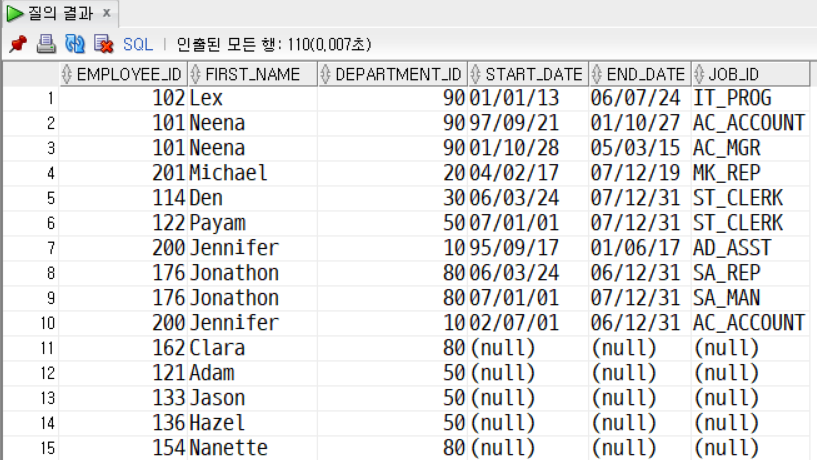
SELECT
e.employee_id, e.first_name,
e.department_id,
j.start_date, j.end_date, j.job_id
FROM employees e, job_history j
WHERE e.employee_id = j.employee_id(+);
외부 조인 진행 시 모든 조건에 (+)를 붙여야 하며, 일반 조건에도 (+)를 붙이지 않으면 데이터가 누락될 현상이 발생한다.
Inner Join
SELECT * FROM info
INNER JOIN auth
ON info.auth_id = auth.auth_id;
SELECT info.auth_id, title, content, name
FROM info
INNER JOIN auth
ON info.auth_id = auth.auth_id;
SELECT
i.auth_id, i.title, i.content, a.name
FROM info i
INNER JOIN auth a
ON i.auth_id = a.auth_id
WHERE a.name = '이순신';
Outer Join
SELECT *
FROM info i
LEFT OUTER JOIN auth a
ON i.auth_id = a.auth_id;
SELECT *
FROM info i
RIGHT OUTER JOIN auth a
ON i.auth_id = a.auth_id;
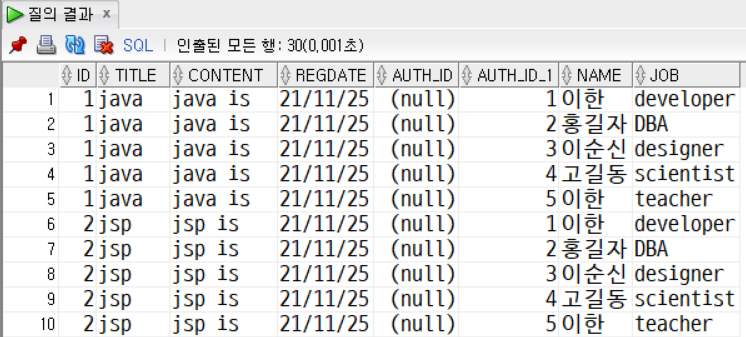
Cross Join
SELECT * FROM info
CROSS JOIN auth
ORDER BY id ASC;
SELECT *
FROM employees e
LEFT OUTER JOIN departments d ON e.department_id = d.department_id
LEFT OUTER JOIN locations loc ON d.department_id = loc.location_id;
SQL Quiz03
문제1. EMPLOYEES 테이블과 , DEPARTMENTS 테이블은 DEPARTMENT_ID로 연결되어 있다. EMPLOYEES, DEPARTMENTS 테이블을 엘리어스를 이용해서 각각 INNER , LEFT OUTER, RIGHT OUTER, FULL OUTER 조인한다. (달라지는 행의 개수 확인)
SELECT *
FROM employees e
INNER JOIN departments d
ON e.department_id = d.department_id;
SELECT *
FROM employees e
LEFT OUTER JOIN departments d
ON e.department_id = d.department_id;
SELECT *
FROM employees e
RIGHT OUTER JOIN departments d
ON e.department_id = d.department_id;
문제2. EMPLOYEES, DEPARTMENTS 테이블을 INNER JOIN 한다.
조건1) employee_id 가 200 인 사람의 이름 , department_id 를 출력한다. 조건2) 이름 컬럼은 first_name 과 last_name 을 합쳐서 출력한다.
SELECT
e.first_name || ' ' || e.last_name AS name,
d.department_id
FROM employees e
INNER JOIN departments d
ON e.department_id = d.department_id
WHERE e.employee_id = 200;
문제3. EMPLOYEES, JOBS 테이블을 INNER JOIN 한다.
조건) 모든 사원의 이름과 직무아이디 , 직무 타이틀을 출력하고 , 이름 기준으로 오름차순 정렬 HINT) 어떤 컬럼으로 서로 연결되 있는지 확인
SELECT
e.first_name, e.job_id, j.job_title
FROM employees e
INNER JOIN jobs j
ON e.job_id = j.job_id
ORDER BY e.first_name ASC;
문제4. JOBS 테이블과 JOB_HISTORY 테이블을 LEFT_OUTER JOIN 한다.
SELECT *
FROM jobs j
LEFT OUTER JOIN job_history jh
ON jh.job_id = j.job_id;
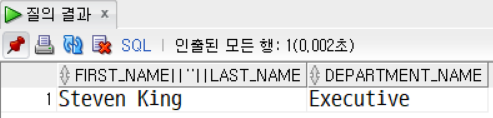
문제5. Steven King 의 부서명을 출력한다.
SELECT
first_name||' '||last_name,
d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON e.department_id = d.department_id
WHERE e.first_name = 'Steven'
AND e.last_name = 'King';
SELECT
e.employee_id, e.first_name, e.salary,
d.department_name, d.location_id
FROM employees e
INNER JOIN departments d
ON e.department_id = d.department_id
WHERE e.job_id = 'SA_MAN';
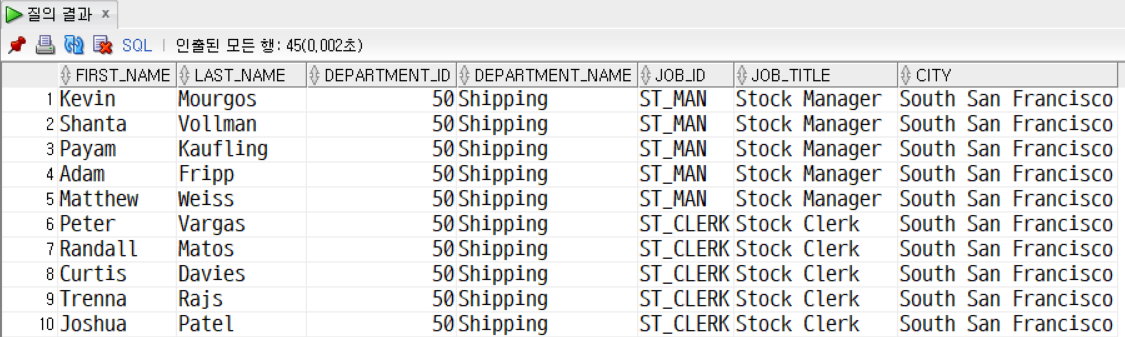
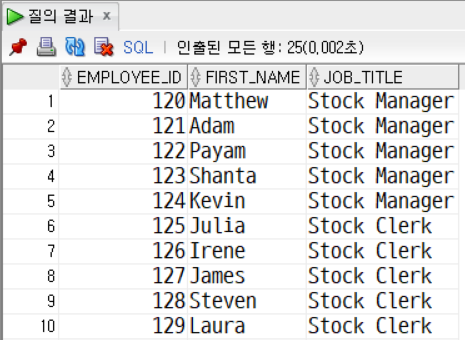
문제8. employees, jobs 테이블을 조인 지정하고 job_title 이 'Stock Manager', 'Stock 인 직원 정보만 출력한다.
SELECT
e.employee_id, e.first_name, j.job_title
FROM employees e
INNER JOIN jobs j
ON e.job_id = j.job_id
WHERE job_title IN ('Stock Manager', 'Stock Clerk');
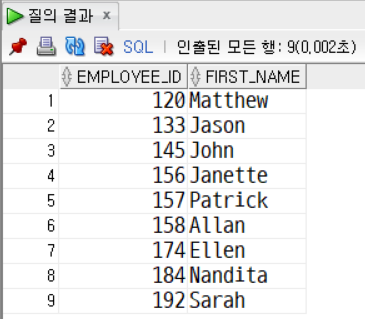
문제9. departments 테이블에서 직원이 없는 부서를 찾아 출력하세요 . LEFT OUTER JOIN 사용
SELECT
d.department_name
FROM departments d
LEFT OUTER JOIN employees e
ON d.department_id = e.department_id
WHERE e.employee_id IS NULL;
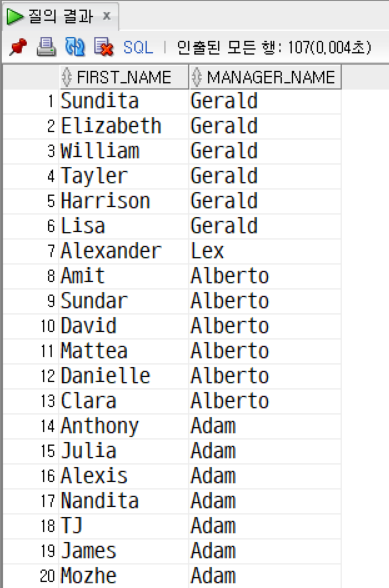
문제10. join 을 이용해서 사원의 이름과 그 사원의 매니저 이름을 출력한다.
힌트) EMPLOYEES 테이블과 EMPLOYEES 테이블을 조인한다.
SELECT
e1.first_name, e2.first_name AS manager_name
FROM employees e1
LEFT JOIN employees e2
ON e1.manager_id = e2.employee_id;
문제11. 문제6번 부분에 EMPLOYEES 테이블에서 left join 하여 관리자 매니저와, 매니저의 이름, 매니저의 급여 까지 출력한다. 매니저 아이디가 없는 사람은 배제하고 급여는 역순으로 출력한다.
SELECT
e1.employee_id, e1.first_name, e1.manager_id,
e2.first_name, e2.job_id, e2.salary
FROM employees e1
LEFT JOIN employees e2
ON e1.manager_id = e2.employee_id
WHERE e1.manager_id IS NOT NULL
ORDER BY e1.salary DESC;


















































댓글